目前分類:未分類文章 (1135)
- May 30 Wed 2018 11:26
虛擬實境進修 說話緩慢兒猛進步
- May 30 Wed 2018 02:49
說話遲緩/兒童說話溝通有障礙?3點判斷問題主因(udn健康醫藥2012
- May 30 Wed 2018 02:49
Google即時語音翻譯 @ 軟體利用講授
- May 30 Wed 2018 02:03
針灸、用藥刺激大腦皮質區 改良自閉症說話能力
- May 29 Tue 2018 17:15
哈梅溫莎小鎮靜終身 全球近10億人見證 婚禮優雅貴氣 梅根受封薩塞克斯公爵夫人
- May 29 Tue 2018 08:49
[問題] WIN10 說話不克不及選繁體中文
古希伯來文翻譯功課系統:WIN10專業版 Service Pack:版本1511(OS10586.36) 産生問題頻率:更新完WIN10以後就一直如許 是否有做Windows Update:有 問題內容:更新完以後語言就一向是香港繁中 想把說話更新成台灣繁中都沒有舉措 一按進去繁體中文選擇的處所就會釀成整片灰色沒辦法按 http://imgur.com/fQ2zSgZ
香港繁中版本 相幹的訊息就一向跑出香港的資訊 感覺很困擾 進展有高手能幫幫天成翻譯公司 我上彀查了好幾個小時都找不到近似的情形- May 29 Tue 2018 08:41
你製造的是能量字仍是汙染字?
- May 29 Tue 2018 00:13
Amazfit米動手錶芳華版 使用與錶盤設置裝備擺設交換
- May 28 Mon 2018 15:30
不是權威不出版:雅思權勢巨子教你征服雅思單字(隨書附…
- May 28 Mon 2018 07:04
Samung s2 中文說話設定
- May 27 Sun 2018 22:37
[德國打工度假] 糊口開消記帳 (更新12月開銷)
- May 27 Sun 2018 13:58
[心得] 曼谷泰文說話學校保舉&各膏火比較
泰米爾語翻譯網誌圖文好讀版 >> http://bit.ly/bkkthai https://pic.pimg.tw/eatnplay/1499792998-2762695072_n.jpg

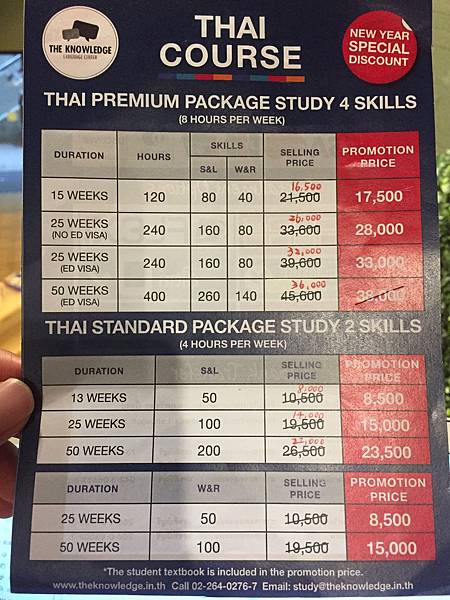
- May 27 Sun 2018 05:33
購物網口碑貓在平溪:明信片獨家款話題@博客來 好書線上優惠
- May 26 Sat 2018 21:09
C/C++說話新手十三誡
翻譯文件推薦C/C++ 說話新手十三誡(The Thirteen Commandments for Newbie C/C++ Programmers) by Khoguan Phuann 請留意: (1) 本篇旨在提醒新手,避免初學常犯的毛病(其實老手也常犯:-Q)翻譯 但不能取代完整的進修,請本身好好研讀一兩本 C 說話的好書, 並多多實作實習。 (2) 強烈建議新手先看過此文再發問,翻譯公司的問題極可能此文已提出並 解答了。 (3) 以下所舉的毛病例子如果在你的電腦上印出和正確例子相同的結果, 那只是不足為恃的一時僥倖。 (4) 不守十三誡者,輕則履行效果的輸出數據錯誤,或是程式當掉,重則 引爆核彈、撲滅地球(若是你的 C 程式是用來節制核彈發射器的話)。 ============================================================= 目錄: (頁碼/行號) 2/24 01. 不行以利用還沒有賜與適當初值的變數 3/46 02. 不克不及存取跨越陣列既定範圍的空間 5/90 03. 不可以提取不知指向何方的指標 7/134 04. 不要試圖用 char* 去更改一個"字串常數" 12/244 05. 不克不及在函式中回傳一個指向區域性主動變數的指標 16/332 06. 不行以只做 malloc()翻譯社 而不做相應的 free() 19/398 07. 在數值運算、賦值或對照中不成以隨便混用分歧型另外數值 21/442 08. ++i/i++/--i/i--/f(&i)哪一個先執行跟遞次有關 24/508 09. 慎用Macro 27/574 10. 不要在 stack 設置過大的變數以免堆疊溢位(stack overflow) 32/684 11. 使用浮點數正確度釀成的誤差問題 35/750 12. 不要猜想二維陣列可以用 pointer to pointer 來傳遞 36/772 13. 函式內 new 出來的空間記得要讓主程式的指標接住 40/860 直接輸入數字可跳至該頁碼 或用:指令輸入行號 01. 你弗成以利用還沒有給予恰當初值的變數 毛病例子: int accumulate(int max) /* 從 1 累加到 max,傳回效果 */ { int sum; /* 未賜與初值的區域變數,其內容值是垃圾 */ for (int num = 1; num <= max; num++) { sum += num; } return sum; } 准確例子: int accumulate(int max) { int sum = 0; /* 正確的付與恰當的初值 */ for (int num = 1; num <= max; num++) { sum += num; } return sum; } 備註: 按照 C Standard,具有靜態貯存期(static storage duration)的變數, 例如 全域變數(global variable)或帶有 static 潤飾符者等, 假如沒有顯式初始化的話,憑據分歧的資料型態予以進行以下初始化: 若變數為算術型別 (int 翻譯社 double , ...) 時,初始化為零或正零。 若變數為指標型別 (int*, double*翻譯社 ...) 時,初始化為 null 指標。 若變數為複合型別 (struct, double _Complex, ...) 時,遞迴初始化所有成員。 若變數為聯合型別 (union) 時,只有個中的第一個成員會被遞迴初始化翻譯 (以上感激Hazukashiine板友斧正) (然則有些MCU 編譯器可能不理會這個劃定,所以照舊請養成設定初值的好習慣) 增補資料: - 精髓區z->5->1->1->1 - C11 Standard 5.1.2, 6.2.4, 6.7.9 02. 你不成以存取超過陣列既定局限的空間 毛病例子: int str[5]; for (int i = 0 ; i <= 5 ; i++) str[i] = i; 准確例子: int str[5]; for (int i = 0; i < 5; i++) str[i] = i; 說明:宣佈陣列時,所給的陣列元素個數值假如是 N翻譯社 那麼天成翻譯公司們在後面 透過 [索引值] 存取其元素時,所能使用的索引值局限是從 0 到 N-1 C/C++ 為了履行效力,其實不會主動查抄陣列索引值是不是跨越陣列鴻溝, 我們要本身來確保不會越界。一旦越界,操作的不再是正當的空間, 將致使沒法預期的後果。 備註: C++11以後可以用Range-based for loop提取array、 vector(或是其他有供給准確.begin()和.end()的class)內的元素 可以確保提取的元素必然落在准確規模內翻譯 例: // vector std::vector<int> v = {0, 1, 2, 3, 4翻譯社 5}; for(const int &i : v) // access by const reference std::cout << i << ' '; std::cout << ' '; // array int a[] = {0, 1, 2翻譯社 3, 4, 5}; for(int n: a) // the initializer may be an array std::cout << n << ' '; std::cout << ' '; 彌補資料: http://en.cppreference.com/w/cpp/language/range-for 03. 你不成以提取(dereference)不知指向何方的指標(包括 null 指標)。 毛病例子: char *pc1; /* 未賜與初值,不知指向何方 */ char *pc2 = NULL; /* pc2 肇端化為 null pointer */ *pc1 = 'a'; /* 將 'a' 寫到不知何方,毛病 */ *pc2 = 'b'; /* 將 'b' 寫到「位址0」,毛病 */ 正確例子: char c; /* c 的內容尚未起始化 */ char *pc1 = &c; /* pc1 指向字元變數 c */ *pc1 = 'a'; /* c 的內容變為 'a' */ /* 動態分配 10 個 char(其值未定),並將第一個char的位址賦值給 pc2 */ char *pc2 = (char *) malloc(10); pc2[0] = 'b'; /* 動態配置來的第 0 個字元,內容變為 'b' free(pc2); 申明:指標變數必須先指向某個可以合法操作的空間,才能進行操作翻譯 ( 使用者記得要檢查 malloc 回傳是否為 NULL, 礙於篇幅本文假定使用上皆正當,也有准確清償記憶體 ) 錯誤例子: char *name; /* name 尚未指向有效的空間 */ printf("Your name翻譯社 please: "); fgets(name,20翻譯社stdin); /* 您肯定要寫入的那塊空間正當嗎??? */ printf("Hello, %s "翻譯社 name); 准確例子: /* 假如編譯期就可以決議字串的最大空間,那就不要宣告成 char* 改用 char[] */ char name[21]; /* 可讀入字串最長 20 個字元,保存一格空間放 '\0' */ printf("Your name, please: "); fgets(name,20,stdin); printf("Hello翻譯社 %s ", name); 准確例子(2): 若是在履行期間才能決意字串的最大空間,C提供兩種作法: a. 使用 malloc() 函式來動態分配空間,用malloc宣佈的陣列會被存在heap 須注意:若是宣佈較大陣列,要確認malloc的回傳值是不是為NULL size_t length; printf("請輸入字串的最大長度(含null字元): "); scanf("%u"翻譯社 &length); name = (char *)malloc(length); if (name) { // name != NULL printf("您輸入的是 %u ", length); } else { // name == NULL puts("輸入值太大或系統已無足夠空間"); } /* 最跋文得 free() 掉 malloc() 所分派的空間 */ free(name); name = NULL; //(註1) b. C99開始可以使用variable-length array (VLA) 須注重: - 因為VLA是被存放在stack裡,利用前要確認array size不能太大 - 不是每一個compiler都支援VLA(註2) - C++ Standard不支援(雖然有些compiler支援) float read_and_process(int n) { float vals[n]; for (int i = 0; i < n; i++) vals[i] = read_val(); return process(vals, n); } 准確例子(3): C++的利用者也有兩種作法: a. std::vector (不管你的陣列巨細會不會變都可用) std::vector<int> v1; v1.resize(10); // 從頭設定vector size b. C++11以後,若是肯定陣列大小不會變,可以用std::array 須留意:一般利用下(存在stack)一樣要確認array size不克不及太大 std::array<int翻譯社 5> a = { 1翻譯社 2, 3 }; // a[0]~a[2] = 1,2,3; a[3]以後為0; a[a.size() - 1] = 5; // a[4] = 0; 備註: 註1. C++的利用者,C++03或之前請用0代替NULL,C++11起頭請改用nullptr 註2. gcc和clang支援VLA,Visual C++不支援 彌補資料: http://www.cplusplus.com/reference/vector/vector/resize/ 04. 你不可以試圖用 char* 去更改一個"字串常數" 試圖去更改字串常數(string literal)的後果會是undefined behavior翻譯 錯誤例子: char* pc = "john"; /* pc 目下當今指著一個字串常數 */ *pc = 'J'; /* undefined behaviour,了局沒法猜測*/ pc = "jane"; /* 正當,pc指到在此外位址的另外一個字串常數*/ /* 然則"john"這個字串照樣存在本來的處所不會消失*/ 因為char* pc = "john"這個動作會新增一個內含元素為"john\0"的static char[5], 然後pc會指向這個static char的位址(每每是唯讀)。 若是試圖存取這個static char[],Standard並沒有定義成效為何。 pc = "jane" 這個動作會把 pc 指到另外一個沒在用的位址然後新增一個 內含元素為"jane\0"的static char[5]翻譯 可是之前阿誰字串 "john " 還是留在原地沒有消逝。 通常編譯器的作法是把字串常數放在一塊read only(.rdata)的區域內, 此區域巨細是有限的,所以如果你反複把pc指給分歧的字串常數, 是有可能會出問題的。 准確例子: char pc[] = "john"; /* pc 如今是個正當的陣列,裡面住著字串 john */ /* 也就是 pc[0]='j', pc[1]='o', pc[2]='h'翻譯社 pc[3]='n', pc[4]='\0' */ *pc = 'J'; pc[2] = 'H'; 申明:字串常數的內容應當如果"唯讀"的。您有使用權,然則沒有更改的權力。 若您希望利用可以更改的字串,那您應該將其放在正當空間 錯誤例子: char *s1 = "Hello, "; char *s2 = "world!"; /* strcat() 不會另行設置裝備擺設空間,只會將資料附加到 s1 所指唯讀字串的後面, 造成寫入到程式無權碰觸的記憶體空間 */ strcat(s1, s2); 准確例子(2): /* s1 宣佈成陣列,並保留足夠空間寄存後續要附加的內容 */ char s1[20] = "Hello翻譯社 "; char *s2 = "world!"; /* 因為 strcat() 的返回值等於第一個參數值,所以 s3 就不需要了 */ strcat(s1, s2); C++對於字串常數的嚴酷界說為const char* 或 const char[]。 但是由於要相容C,char* 也是許可的寫法(不建議就是)。 不過,在C++試圖更改字串常數(要先const_cast)一樣是undefined behavior翻譯 const char* pc = "Hello"; char* p = const_cast<char*>(pc); p[0] = 'M'; // undefined behaviour 備註: 由於不加const容易造成攪渾, 建議不論是C照樣C++一概用 const char* 界說字串常數。 補充資料: http://en.cppreference.com/w/c/language/string_literal http://en.cppreference.com/w/cpp/language/string_literal 字串函數相關:#1IOXeMHX undefined behavior : 精髓區 z -> 3 -> 3 -> 23 05. 你不行以在函式中回傳一個指向區域性主動變數的指標。不然,會得到垃圾值 [感謝 gocpp 網友提供程式例子] 毛病例子: char *getstr(char *name) { char buf[30] = "hello, "; /*將字串常數"hello, "的內容複製到buf陣列*/ strcat(buf, name); return buf; } 申明:區域性主動變數,將會在脫離該區域時(本例中就是從getstr函式返回時) 被祛除,是以呼叫端獲得的指標所指的字串內容就失效了翻譯 准確例子: void getstr(char buf[]翻譯社 int buflen翻譯社 char const *name) { char const s[] = "hello, "; strcpy(buf翻譯社 s); strcat(buf翻譯社 name); } 准確例子: int* foo() { int* pInteger = (int*) malloc( 10*sizeof(int) ); return pInteger; } int main() { int* pFromfoo = foo(); } 說明:上例固然回傳了函式中的指標,但由於指標內容所指的位址並非區域變數, 而是用動態的方式抓取而得,換句話說這塊空間是長在 heap 而非 stack, 又因 heap 空間其實不會主動收受接管,是以這塊空間在分開函式後,依然有效 (但是這個例子可能會因為 programmer 的忽視,忘記 free 而造成 memory leak) [針對字串操作,C++提供了更方便平安更直觀的 string class, 能用就盡可能用] 准確例子: #include <string> /* 並不是 #include <cstring> */ using std::string; string getstr(string const &name) { return string("hello, ") += name; } 06. [C]你弗成以只做 malloc(), 而不做響應的 free(). 否則會造成記憶體漏失 但若不是用 malloc() 所得到的記憶體,則不可以 free()。已 free()了 所指記憶體的指標,在它指向另外一塊有用的動態分配得來的空間之前,弗成 以再被 free(),也不成以提取(dereference)這個指標翻譯 小技能: 可在 free 以後將指標指到 NULL,free不會對空指標作用。 例: int *p = malloc(sizeof(int)); free(p); p = NULL; free(p); // free不會對空指標有感化 [C++] 你不可以只做 new, 而不做響應的 delete (除unique_ptr以外) 註:new 與 delete 對應,new[] 與 delete[] 對應, 不可與malloc/free混用(結果弗成展望) 切記,做了幾回 new,就必須做幾次 delete 小技巧: 可在 delete 以後將指標指到0或nullptr(C++11起頭), 由於 delete 自己會先做搜檢,因此可以免掉屢次 delete 的毛病 准確例子: int *ptr = new int(99); delete ptr; ptr = nullptr; delete ptr; /* delete 只會處理指向非 NULL 的指標 */ 備註: C++11後新增智能指標(smart pointer): unique_ptr 當unique_ptr所指物件消逝時,會主動釋放其記憶體,不需要delete。 例: #include <memory> // 含unique_ptr的標頭檔 std::unique_ptr<int> p1(new int(5)); 彌補資料: http://en.cppreference.com/w/cpp/memory/unique_ptr 07. 你不行以在數值運算、賦值或比較中隨便混用分歧型另外數值,而不隆重考 慮數值型別轉換可能帶來的「意外驚喜」(錯愕)。必需隨時注重數值運算 的結果,其局限是否會超出變數的型別 毛病例子: unsigned int sum = 2000000000 + 2000000000; /* 超越 int 寄存規模 */ unsigned int sum = (unsigned int) (2000000000 + 2000000000); double f = 10 / 3; 准確例子: /* 掃數都用 unsigned int翻譯社 注重數字後面的 u, 大寫 U 同樣成 */ unsigned int sum = 2000000000u + 2000000000u; /* 或是用顯式的轉型 */ unsigned int sum = (unsigned int) 2000000000 + 2000000000; double f = 10.0 / 3.0; 毛病例子: unsigned int a = 0; int b[10]; for(int i = 9 ; i >= a ; i--) { b[i] = 0; } 申明:由於 int 與 unsigned 配合運算的時刻,會轉換 int 為 unsigned, 因此迴圈前提永久知足,與預期行為不符 毛病例子: (感謝 sekya 網友供給) unsigned char a = 0x80; /* no problem */ char b = 0x80; /* implementation-defined result */ if( b == 0x80 ) { /* 不一定恒真 */ printf( "b ok " ); } 申明:說話並未劃定 char 生成為 unsigned 或 signed,是以將 0x80 放入 char 型態的變數,將會視各家編譯器不同作法而有不同成效 錯誤例子(以下假定為在32bit機械上履行): #include <math.h> long a = -2147483648 ; // 2147483648 = 2 的 31 次方 while (labs(a)>0){ // labs(-2147483648)<0 有可能産生 ++a; } 申明:如果你去看C99/C11 Standard,翻譯公司會發現long 變數的最大/最小值為(被define在limits.h) LONG_MIN -2147483647 // compiler實作時最小值不成大於 -(2147483648-1) LONG_MAX 2147483647 // compiler實作時最小值不可小於 (2147483648-1) 不外由於32bit能顯示的局限就是2**32種,所以一般16/32bit功課系統會把 LONG_MIN多減去1,也就是int 的顯示規模為(-LONG_MAX - 1) ~ LONG_MAX。 (64bit的功課系統long多為8 bytes,但是照舊符合Standard要求的最小規模) 當程式跑到labs(-2147483648)>0時,由於2147483648大於LONG_MAX, Standard告訴我們,當labs的結果沒法被long有限的範圍默示, 編譯器會怎麼幹就看他喜悅(undefined behavior)。 (不只long,其他如int、long long等以此類推) 彌補資料: - C11 Standard 5.2.4.2.1翻譯社 7.22.6.1 - https://www.fefe.de/intof.html 08. ++i/i++/--i/i--/f(&i)哪一個先執行跟挨次有關 ++i/i++ 和--i/i-- 的問題幾乎每月都邑出現,所以稀奇強調翻譯 當一段程式碼中,某個變數的值用某種體例被改變一次以上, 例如 ++x/--x/x++/x--/function(&x)(能改變x的函式) - 假如Standard沒有分外去界說某段敘述中哪一個部份必需被先履行, 那成效會是undefined behavior(後果未知)。 - 若是Standard有特別去定義履行順序,那結果就憑據執行挨次決意翻譯 C/C++均正確的例子: if (--a || ++a) {} // ||左側先計較,如果左邊為1右邊就不會算 if (++i && f(&i)) {} // &&左側先計算,如果左側為0右邊就不會算 a = (*p++) ? (*p++) : 0 ; // 問號左側先較量爭論 int j = (++i, i++); // 這裡的逗號為運算子,表示依序計較 C/C++均毛病的例子: int j = ++i + i++; // undefined behavior,Standard沒界說+號哪邊先執行 x = x++; // undefined behavior, Standard沒界說=號哪邊先執行 printf( "%d %d %d", I++, f(&I), I++ ); // undefined behavior翻譯社 原因同上 foo(i++, i++); // undefined behavior,這裡的逗號是用來分隔引入參數的 // 分隔符(separator)而非運算子,Standard沒界說哪邊先履行 在C與C++03毛病可是在C++11最先(但不包括C)正確的例子: C++11中,++i/--i為左值(lvalue),i++/i--為右值(rvalue)。 左值可以被assign value給它,右值則不可。 而在C中,++i/--i/i++/i--都是右值翻譯 所以以下的code在C++會准確,C則否。 ++++++++++phew ; // C++11會把它注釋為++(++(++(++(++phew)))); i = v[++i]; // ++i會先完成 i = ++i + 1; // ++i會先完成 在C++17起頭(但不包括C)才正確的例子: cout << i << i++; // 先左後右 a[i] = i++; // i++先做 a[x++] = --x; // 先處理--x,再處置a[x++] (loveflames增補) 增補資料 - Undefined behavior and sequence points http://stackoverflow.com/questions/4176328/undefined-behavior-and- sequence-points) - C11 Standard 6.5.13-17,Annex C - Sequence poit https://en.wikipedia.org/wiki/Sequence_point - Order of evaluation http://en.cppreference.com/w/cpp/language/eval_order 09. 慎用macro(#define) Macro是個像鐵鎚一樣好用又危險的東西: 用得好可以釘釘子,用不好可以把釘子打彎、敲到翻譯公司手指或被抓去吃槍彈。 因為macro 界說出的「偽函式」有以下瑕玷: (1) debug會變得複雜。 (2) 無法遞迴呼喚。 (3) 沒法用 & 加在 macro name 之前,獲得函式位址。 (4) 沒有namespace。 (5) 可能會致使希奇的side effect或其他無法展望的問題翻譯 所以,利用macro前,請先確認以上的瑕玷是不是會影響翻譯公司的程式運行翻譯 替換方案:enum(定義整數),const T(定義常數),inline function(界說函式) C++的template(界說可用不同type參數的函式), 或C++11入手下手的匿名函式(Lambda function)與constexpr T(編譯期常數) 以下就針對macro的錯誤謬誤做申明: (1) debug會變得複雜翻譯 編譯器不克不及對macro自己做語法檢查,只能檢查預處理(preprocess)後的成效。 (2) 沒法遞迴呼喚。 憑據C standard 6.10.3.4, 假如某macro的界說裡裏面含有跟此macro名稱一樣的的字串, 該字串將不會被預處置。 所以: #define pr(n) ((n==1)? 1 : pr(n-1)) cout<< pr(5) <<endl; 預處置懲罰事後會釀成: cout<< ((5==1)? 1 : pr(5 -1)) <<endl; // pr沒有界說,編譯會犯錯 (3) 沒法用 & 加在 macro name 之前,取得函式位址。 因為他不是函式,所以翻譯公司也不可以把函式指標套用在macro上。 (4) 沒有namespace。 錯誤例子: #define begin() x = 0 for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) // begin是std的保存字 std::cout << ' ' << *it; 改良方式:macro名稱一概用大寫,如BEGIN() (5) 可能會導致奇怪的side effect或其他無法猜測的問題翻譯 錯誤例子: #include <stdio.h> #define SQUARE(x) (x * x) int main() { printf("%d ", SQUARE(10-5)); // 預處置後釀成SQUARE(10-5*10-5) return 0; } 正確例子:在 Macro 定義中, 務必為它的參數個別加上括號 #include <stdio.h> #define SQUARE(x) ((x) * (x)) int main() { printf("%d ", SQUARE(10-5)); return 0; } 不過遇到以下有side effect的例子就算加了括號也沒用。 錯誤例子: (感激 yaca 網友供給) #define MACRO(x) (((x) * (x)) - ((x) * (x))) int main() { int x = 3; printf("%d ", MACRO(++x)); // 有side effect return 0; } 彌補資料: - http://stackoverflow.com/questions/14041453/why-are-preprocessor- macros-evil-and-what-are-the-alternatives - http://stackoverflow.com/questions/12447557/can-we-have-recursive-macros - C11 Standard 6.10.3.4 - http://en.cppreference.com/w/cpp/language/lambda 10. 不要在 stack 設置過大的變數以避免堆疊溢位(stack overflow) 由於編譯器會自行決定 stack 的上限,某些預設是數 KB 或數十KB,當變數所需的空 間過大時,很輕易造成 stack overflow,程式亦隨之當掉(segmentation fault)。 可能造成堆疊溢位的原因包羅遞迴太屢次(多為程式設計缺點), 或是在 stack 設置過大的變數。 錯誤例子: int array[10000000]; // 在stack宣告過大陣列 std::array<int翻譯社 10000000> myarray; //在stack宣佈過大std::array 准確例子: C: int *array = (int*) malloc( 10000000*sizeof(int) ); C++: std::vector<int> v; v.resize(10000000); 說明:建議將使用空間較大的變數用malloc/new配置在 heap 上,由於此時 stack 上只需設置裝備擺設一個 int* 的空間指到在heap的該變數,可避免 stack overflow翻譯 利用 heap 時,雖然整個 process 可用的空間是有限的,但採用動態抓取 的方式,new 沒法設置裝備擺設時會丟出 std::bad_alloc 例外,malloc 無法設置裝備擺設 時會回傳 null(註2),不會影響到正常利用下的程式功能 備註: 註1. 利用 heap 時,整個 process 可用的空間一樣是有限的,若是需要頻繁地 malloc / free 或 new / delete 較大的空間,需留意避免造成記憶體破裂 (memory fragmentation)。 註2. 由於Linux利用overcommit機制治理記憶體,malloc即便在記憶體不足時 依然會回傳非NULL的address,一樣情形在Windows/Mac OS則會回傳NULL (感謝 LiloHuang 補充) 彌補資料: - https://zh.wikipedia.org/wiki/%E5%A0%86%E7%96%8A%E6%BA%A2%E4%BD%8D - http://stackoverflow.com/questions/3770457/what-is-memory-fragmentation - http://library.softwareverify.com/memory-fragmentation-your-worst-nightmare/ overcommit跟malloc: - http://goo.gl/V9krbB - http://goo.gl/5tCLQc 11. 使用浮點數萬萬要注重精確度所釀成的誤差問題 憑據 IEEE 754 的規範,又電腦中是用有限的二進位儲存數字,因此常有可 能因為精確度而造成誤差,例如加減乘除,等號大小判定,分派律等數學上 經常使用到的操作,很有可能因此而犯錯(不成立) 更詳細的申明可以參考精髓區 z-8-11 或參考冼鏡光先生所揭橥的一文 "利用浮點數最最根基的觀念" http://blog.dcview.com/article.php?a=VmhQNVY%2BCzo%3D 12. 不要猜想二維陣列可以用 pointer to pointer 來傳遞 (感激 loveme00835 legnaleurc 版友的幫手) 首先必需有個觀念,C 語言中陣列是無法直接拿來傳遞的! 不外這時候會有人跳出來反駁: void pass1DArray( int array[] ); int a[10]; pass1DArray( a ); /* 可以正當編譯,並且履行成效准確!! */ 事實上,編譯器會這麼看待 void pass1DArray( int *array ); int a[10]; pass1DArray( &a[0] ); 我們可以趁便看出來,array 變數本身可以 decay 成記憶體開端的位置 因此我們可以 int *p = a; 這類方式,拿指標去接陣列。 也因為上述的例子,許多人以為那二維陣列是否是也能夠改成 int ** 毛病例子: void pass2DArray( int **array ); int a[5][10]; pass2DArray( a ); /* 這時候候編譯器就會報錯啦 */ /* expected ‘int **’ but argument is of type ‘int (*)[10]’*/ 在一維陣列中,指標的移動操作,會剛好籠蓋到陣列的範圍 例如,宣佈了一個 a[10],那我可以把 a 當成指標來操作 *a 至 *(a+9) 是以我們可以獲得一個概念,在操作的時辰,可以 decay 成指標來利用 也就是我可以把一個陣列當做一個指標來利用 (again, 陣列!=指標) 然則多維陣列中,無法如斯利用,事實上這也很直觀,試圖拿一個 pointer to pointer to int 來操作一個 int 二維陣列,這是不公道的! 儘管我們無法將二維陣列直接 decay 成兩個指標,然則我們可以換個角度想, 二維陣列可以算作 "外層大的一維陣列,每一維內層各又包括著一維陣列" 假如想通了這一點,天成翻譯公司們可以仿造之前的規則, 把外層大的一維陣列 decay 成指標,該指標指向內層的一維陣列 void pass2DArray( int (*array) [10] ); // array 是個指標,指向 int [10] int a[5][10]; pass2DArray( a ); 這時候就很好理解了,函數 pass2DArray 內的 array[0] 會代表什麼呢? 答案是它代表著 a[0] 外層的那一維陣列,裡面包含著內層 [0]~[9] 也是以 array[0][2] 就會對應到 a[0][2],array[4][9] 對應到 a[4][9] 結論就是,只有最外層的那一維陣列可以 decay 成指標,其他維陣列都要 明白的指出陣列巨細,如許多維陣列的傳遞就不會有問題了 也因為方才的例子,我們可以清晰的知道在傳遞陣列時,現實行為是在傳遞 指標,也是以若是我們想用 sizeof 來求得陣列元素個數,那是不成行的 毛病例子: void print1DArraySize( int* arr ) { printf("%u"翻譯社 sizeof(arr)/sizeof(arr[0])); /* sizeof(arr) 只是 */ } /* 一個指標的巨細 */ 受此限制,天成翻譯公司們必需手動傳入巨細 void print1DArraySize( int* arr, size_t arrSize ); C++ 供給 reference 的機制,使得我們不需再這麼麻煩, 可以直接傳遞陣列的 reference 給函數,大小也可以直接求出 正確例子: void print1DArraySize( int (&array)[10] ) { // 傳遞 reference cout << sizeof(array) / sizeof(int); // 正確取得陣列元素個數 } 13. 函式內 new 出來的空間記得要讓主程式的指標接住 對指標不熟習的利用者會以為以下的程式碼是吻合預期的 void newArray(int* local, int size) { local = (int*) malloc( size * sizeof(int) ); } int main() { int* ptr; newArray(ptr, 10); } 接著就會找了很久的 bug,最後仍然搞不懂為什麼 ptr 沒有指向剛剛拿到的正當空間 讓我們再回顧一次,並且用圖表示 (感謝Hazukashiine板友供應圖解) ┌────┐ ┌────┐ ┌────┐ ┌────┐ Heap │ │ │ │ │ 新設置裝備擺設 │ │ 已泄露 │ │ │ │ │ │ 的空間 <─┐ │ 的空間 │ │ │ │ │ │(allocd)│ │ │(leaked)│ │ │ │ │ ├────┤ │ ├────┤ │ │ │ │ │ : │ │ │ │ │ │ │ │ │ : │ │ │ : │ │ │ ├────┤ ├────┤ │ │ : │ │ │ │ local ├─┐ │ local ├─┘ │ │ ├────┤ ├────┤ │ ├────┤ ├────┤ Stack │ ptr ├─┐ │ ptr ├─┤ │ ptr ├─┐ │ ptr ├─┐ └────┘ ╧ └────┘ ╧ └────┘ ╧ └────┘ ╧ 未初始化 函式呼喚 設置裝備擺設空間 函式返回 int *ptr; local = ptr; local = malloc(); 用圖看應當一切就都理解理睬了,天成翻譯公司也不需冗言诠釋 或許有人會想問,指標不是傳址嗎? 切確來說,指標也是傳值,只不外該值是一個位址 (ex: 0xfefefefe) local 接到了 ptr 指向的阿誰位置,接著函式內 local 要到了新的位置 然則 ptr 指向的位置照樣沒變的,是以分開函式後就如同事什麼都沒産生 ( 嚴格說起來還發生了 memory leak ) 以下是一種解決門徑 int* createNewArray(int size) { return (int*) malloc( size * sizeof(int) ); } int main() { int* ptr; ptr = createNewArray(10); } 改成如許亦可 ( 為何用 int** 就能夠?想一想他會傳什麼曩昔給local ) void createNewArray(int** local, int size) { *local = (int*) malloc( size * sizeof(int) ); } int main() { int *ptr; createNewArray(&ptr翻譯社 10); } 假如是 C++,別忘了可以善用 Reference void newArray(int*& local, int size) { local = new int[size]; } 跋文:從「古時辰」撒播下來一篇文章 "The Ten Commandments for C Programmers"(Annotated Edition) by Henry Spencer http://www.lysator.liu.se/c/ten-commandments.html 一方面它不是針對 C 的初學者,一方面它特地模擬中古英文 聖經的用語,寫得文謅謅翻譯所以天成翻譯公司而今別的寫了這篇,進展 能涵蓋最主要的觀念和初學乃至內行最易犯的毛病翻譯 作者:潘科元(Khoguan Phuann) (c)2005. 感激 ptt.cc BBS 的 C_and_CPP 看板眾多網友供應貴重定見及程式實例。 nowar100 屢次加以點竄收拾整頓,擴充至 13 項,而且製作成動畫版翻譯 wtchen 應板友要求移除動畫並憑據C/C++標準點竄內容(Ver.2016) 如發現 Bug 請推文回報,感謝您
- May 26 Sat 2018 12:42
[心得] 說話交換
印度語口譯我說話交換已快三年了,從拿到三級以後入手下手的翻譯 一入手下手我是在師大貼POST,碰到了一個很親切的日本女生叫做KANA。 由於KANA中文不太好,我日文也不敷好 ~"~ 所以如果碰到意思無法表達的時辰,就會肢體語言加畫畫 XD 就這樣互換了一年,我覺得幫助很大。 因為其實學到三級已可以簡單的會話了, 可是因為缺乏自信所以只要一出黉舍就不敢說日文... 跟KANA交換的那一年我們每次紛歧定在固定的處所, 有時辰去咖啡廳有時刻去逛街(逛街時看到契型鞋我還問她日文是什麼 XD), (還會聊什麼衣服都雅或者演藝界八卦~~) 後來也一路去海邊或一些景點什麼的, 多虧了她讓我對於開口說日文有決定信念多了。 後來KANA就回日本了,以後我再去師大貼文碰到的對象就普普 我感覺語言互換很主要的是兩邊都有一顆熱誠想進修的心吧 若是沒有的話,很輕易不了了之 並且即便知道對方想表達的是什麼 也是要有耐煩聽完對方論述 如許彼此才有實習的機遇 後來我又發現了在一個叫做"まるごと台湾"的網站可以認識日本人 誰人網站超多日本人的(我不確定目下當今還有無) 固然那網站看起來超怪的 許多很怪的告白 我一PO文也許20~30人加我MSN吧 可是這其中或許10~20個人是來亂的 只是想聊天 或也有要開是訊給妳看的變態 我只能說每一個國度都有怪人也有大好人呀 XD 然則我也是在まるごと台湾找到了很棒的說話互換相手 他叫KOJI是早稻田畢業還去過英國留學 由於對於說話有興趣又家道不錯所以來台灣學中文 KOJI很棒的是他對中文超有熱忱的 他會看良多台灣片子(李安初期的作品或侯孝賢之類的...) 我們就是固定在台北車站四周的星巴克 他會問我他黉舍教他但他不懂的 而我就單純閒聊 因為我也只想增強會話 就這樣我們交流了一年多快兩年 我從2級到1級到後來研究所 乃至考研究所面試前他還扮黑臉考官陪我練習 問我許多很刁專的問題 成效後來面試當天考官居然還真的問了^^" 後來我也就考上了 XD 後果比來KOJI因為新學期學校上課時候更動 所以我們就沒有繼續互換了 讓我感覺挺遺憾的 我感覺說話交換最棒的處所就是 可以身在台灣就學到良多白話的單字還有說法 建議假如像我們這類沒機遇去留學的人可以試試看唷 不外還是有一點小小要留意的處所 像KOJI跟KANA都告知過我 他們之前碰到其他的相手會問他們有關文法的問題 其實日本人本身也不懂文法 就像我們也不懂中文文法 XD 或是太依靠英文或不好好遵照中日文各半原則等 都邑讓他們不想互換 小小分享本身的心得^^ 各人一路加油~~
- May 26 Sat 2018 04:01
IELTSLifeSkills的測驗內容是甚麼?@公益英語傳教士/世界創富協會...
- May 25 Fri 2018 19:25
變異性語言中的「比方式」研究 〈一〉@moon
- May 25 Fri 2018 19:04
影/超狂!精曉32種說話 歐盟翻譯官:中文最難
- May 25 Fri 2018 18:47
【上海話】為什麼想學上海話?@零極限,說故事
